7.2 KiB
7.2 KiB
| theme | background | title | class | highlighter | drawings | transition | mdc | ||
|---|---|---|---|---|---|---|---|---|---|
| seriph | https://cover.sli.dev | Halide | text-center | shiki |
|
slide-left | true |
Halide
a language and compiler for optimizing parallelism, locality, and recomputation in image processing pipelines
Hongcheng Li
Xinyu Xu
layout: two-cols layoutClass: gap-16
transition: fade-out
What is Halide?
Halide is a domain-specific language (DSL) and compiler
- Designed for image processing pipelines.
- Optimizes parallelism, locality, and recomputation.
- Enables high-level expression of algorithms.
- Automatically applies optimization techniques.
- Generates optimized code for CPUs, GPUs, and specialized units.
- Simplifies development of complex image processing applications.
transition: slide-up mdc: true
Cache
 {width=500px lazy}
{width=500px lazy}
transition: slide-up level: 2 mdc: true
Memory Hierarchy
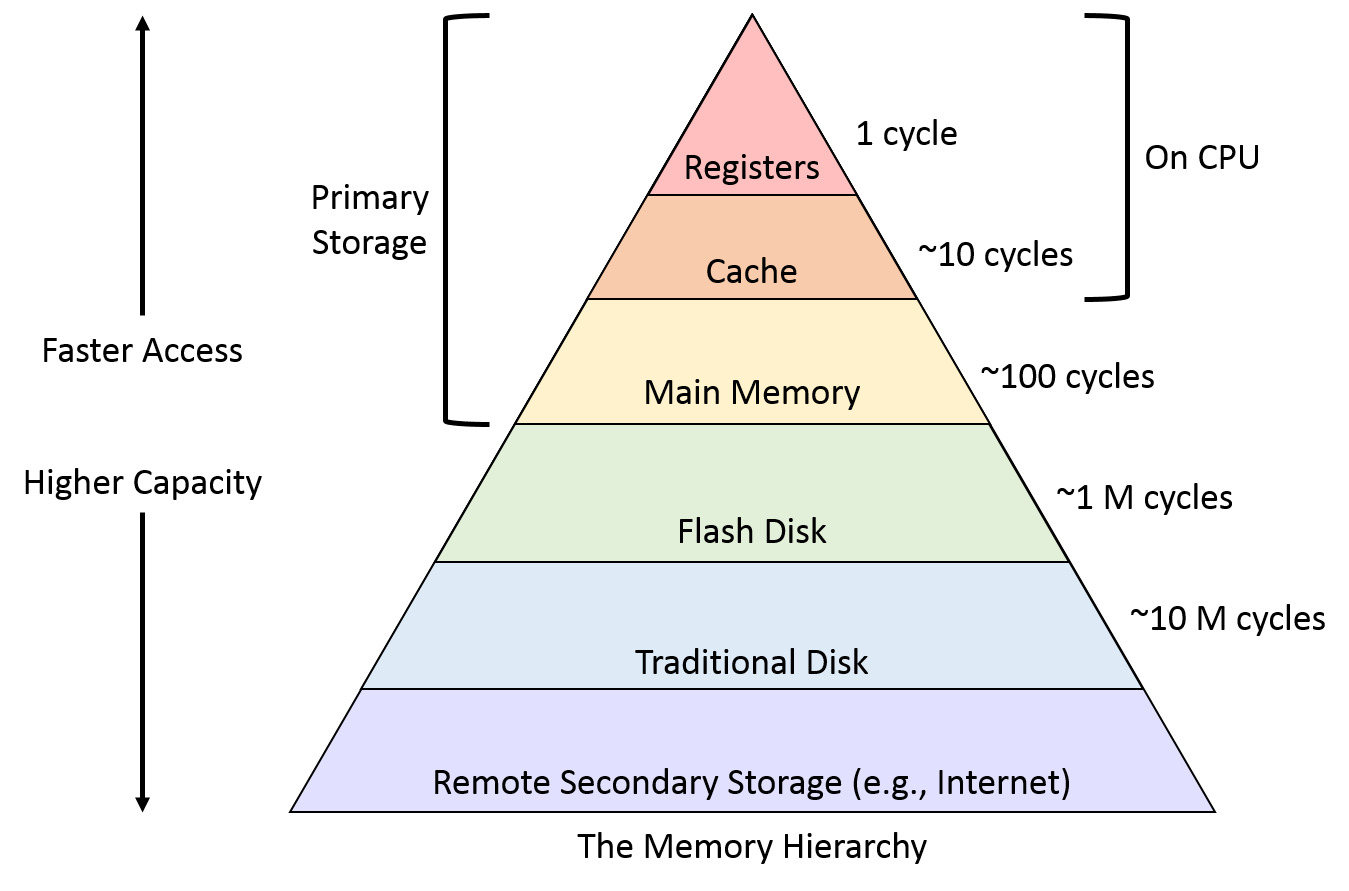 {width=500px lazy}
{width=500px lazy}
transition: slide-up level: 2 mdc: true
Moore's law
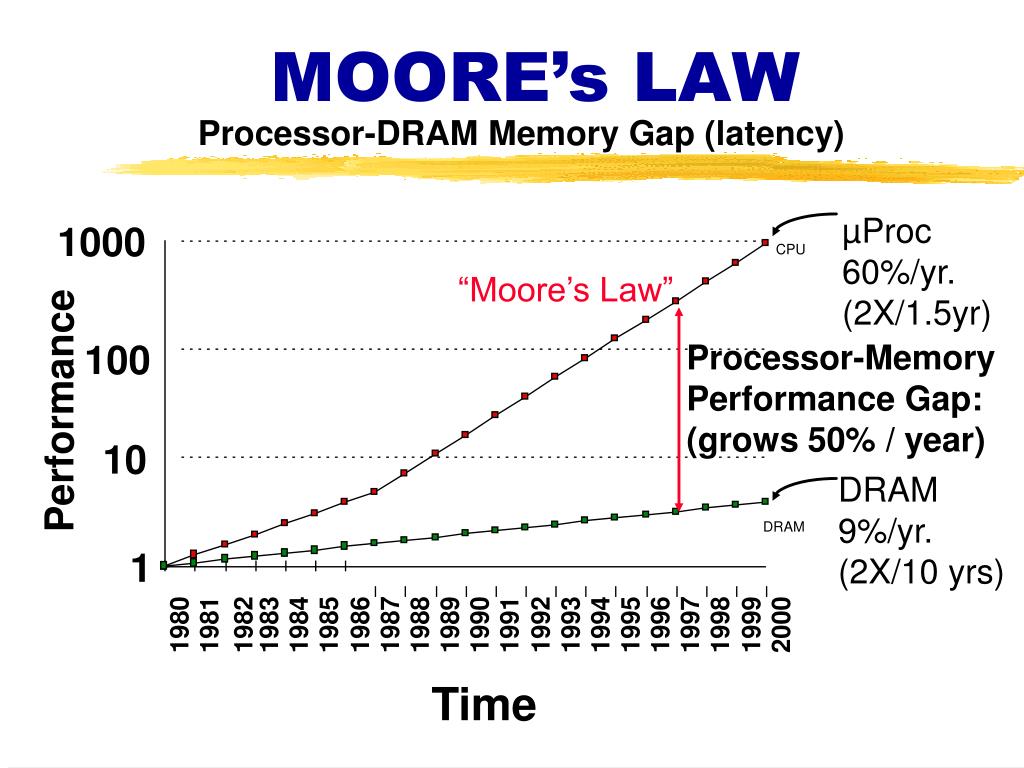 {width=500px lazy}
{width=500px lazy}
transition: slide-up level: 2
Locality
- Temporal Locality
- Spatial Locality
transition: slide-left level: 2
Small Experiment
<<< @/snippets/blur.ts ts {all}{maxHeight:'250px'}
// Paste your code here
//
//
transition: slide-up
A Simple Blur Algorithm
```cpp {all|3|4|all} twoslash
UniformImage in(UInt(8), 2)
Var x, y
Func blurx(x,y) = in(x-1,y) + in(x,y) + in(x+1,y)
Func out(x,y) = blurx(x,y-1) + blurx(x,y) + blurx(x,y+1)
```
```cpp {all} twoslash
UniformImage in(UInt(8), 2)
Var x, y
Func blurx(x,y) = in(x-1,y) + in(x,y) + in(x+1,y)
Func out(x,y) = blurx(x,y-1) + blurx(x,y) + blurx(x,y+1)
// Generated code
alloc blurx[2048][3072]
for each x in 0..3072:
for each y in 0..2048:
blurx[y][x] = in[y][x-1] + in[y][x] + in[y][x+1]
alloc out[2046][3072]
for each x in 0..3072:
for each y in 1..2047:
out[y][x] = blurx[y-1][x] + blurx[y][x] + blurx[y+1][x]
```
```cpp {all|3-4,7-8} twoslash
// Breadth first: each function is entirely evaluated before the next one.
alloc blurx[2048][3072]
for each x in 0..3072:
for each y in 0..2048:
blurx[y][x] = in[y][x-1] + in[y][x] + in[y][x+1]
alloc out[2046][3072]
for each x in 0..3072:
for each y in 1..2047:
out[y][x] = blurx[y-1][x] + blurx[y][x] + blurx[y+1][x]
```
```cpp {all|2-4,6-8} twoslash
// Reorder
alloc blurx[2048][3072]
for each y in 0..2048:
for each x in 0..3072:
blurx[y][x] = in[y][x-1] + in[y][x] + in[y][x+1]
alloc out[2046][3072]
for each y in 1..2047:
for each x in 0..3072:
out[y][x] = blurx[y-1][x] + blurx[y][x] + blurx[y+1][x]
```
```cpp {all|5-7} twoslash
// Total fusion: values are computed on the fly each time that they are needed.
alloc out[2046][3072]
for each y in 1..2047:
for each x in 0..3072:
alloc blurx[-1..1]
for each i in -1..1:
blurx[i] = in[y-1+i][x-1]+in[y-1+i][x]+in[y-1+i][x+1]
out[y][x] = blurx[0] + blurx[1] + blurx[2]
```
```cpp {all|4-5} twoslash
// Sliding window: values are computed when needed then stored until not useful anymore.
alloc out[2046][3072]
alloc blurx[3][3072]
for each y in -1..2047:
for each x in 0..3072:
blurx[(y+1)%3][x] = in[y+1][x-1] + in[y+1][x] + in[y+1][x+1]
if y < 1: continue
out[y][x] = blurx[(y-1)%3][x] + blurx[ y % 3 ][x] + blurx[(y+1)%3][x]
```
```cpp {all} twoslash
// Tiles: overlapping regions are processed in parallel, functions are evaluated one after another.
alloc out[2046][3072]
for each ty in 0..2048/32:
for each tx in 0..3072/32:
alloc blurx[-1..33][32]
for each y in -1..33:
for each x in 0..32:
blurx[y][x] = in[ty*32+y][tx*32+x-1] + in[ty*32+y][tx*32+x] + in[ty*32+y][tx*32+x+1]
for each y in 0..32:
for each x in 0..32:
out[ty*32+y][tx*32+x] = blurx[y-1][x] + blurx[y ][x] + blurx[y+1][x]
```
```cpp {all} twoslash
// Sliding windows within tiles: tiles are evaluated in parallel using sliding windows.
alloc out[2046][3072]
for each ty in 0..2048/8:
alloc blurx[-1..1][3072]
for each y in -2..8:
for each x in 0..3072:
blurx[(y+1)%3][x] = in[ty*8+y+1][tx*32+x-1] + in[ty*8+y+1][tx*32+x] + in[ty*8+y+1][tx*32+x+1]
if each y < 0: continue
for each x in 0..3072:
out[ty*8+y][x] = blurx[(y-1)%3][x] + blurx[ y % 3][x] + blurx[(y+1)%3][x]
```
transition: fade-out
Results
x86
| Algorithm | Halide tuned(ms) | Expert tuned(ms) | Speedup | Lines Halide | Lines Expert | Factor Shorter |
|---|---|---|---|---|---|---|
| Blur | 11 | 13 | 1.2× | 2 | 35 | 18× |
| Bilateral grid | 36 | 158 | 4.4× | 34 | 122 | 4× |
| Camera pipe | 14 | 49 | 3.4× | 123 | 306 | 2× |
| Interpolate | 32 | 54 | 1.7× | 21 | 152 | 7× |
| Local Laplacian | 113 | 189 | 1.7× | 52 | 262 | 5× |
transition: slide-left hideInToc: true
Results
CUDA
| Algorithm | Halide tuned(ms) | Expert tuned(ms) | Speedup | Lines Halide | Lines Expert | Factor Shorter |
|---|---|---|---|---|---|---|
| Bilateral grid | 8.1 | 18 | 2.3× | 34 | 370 | 11× |
| Interpolate | 9.1 | 54* | 5.9× | 21 | 152* | 7× |
| Local Laplacian | 21 | 189* | 9× | 52 | 262* | 5× |
References
- Halide: a language and compiler for optimizing parallelism, locality, and recomputation in image processing pipelines
- CPU die shot
- Memory Hierarchy
- Moore's Law
{kind=link}
{kind=link}
{kind=link}